Compare commits
No commits in common. "91b2b2b9563f3a58e2e202b6569c9b2d4c0893a4" and "96ddf180a98a4cab94e16c6b49396275194dd7e5" have entirely different histories.
91b2b2b956
...
96ddf180a9
3 changed files with 9 additions and 17 deletions
|
|
@ -1,13 +1,9 @@
|
|||
# GeoStat
|
||||
### Version 2.3
|
||||
### Version 2.2
|
||||
|
||||
|
||||
|
||||
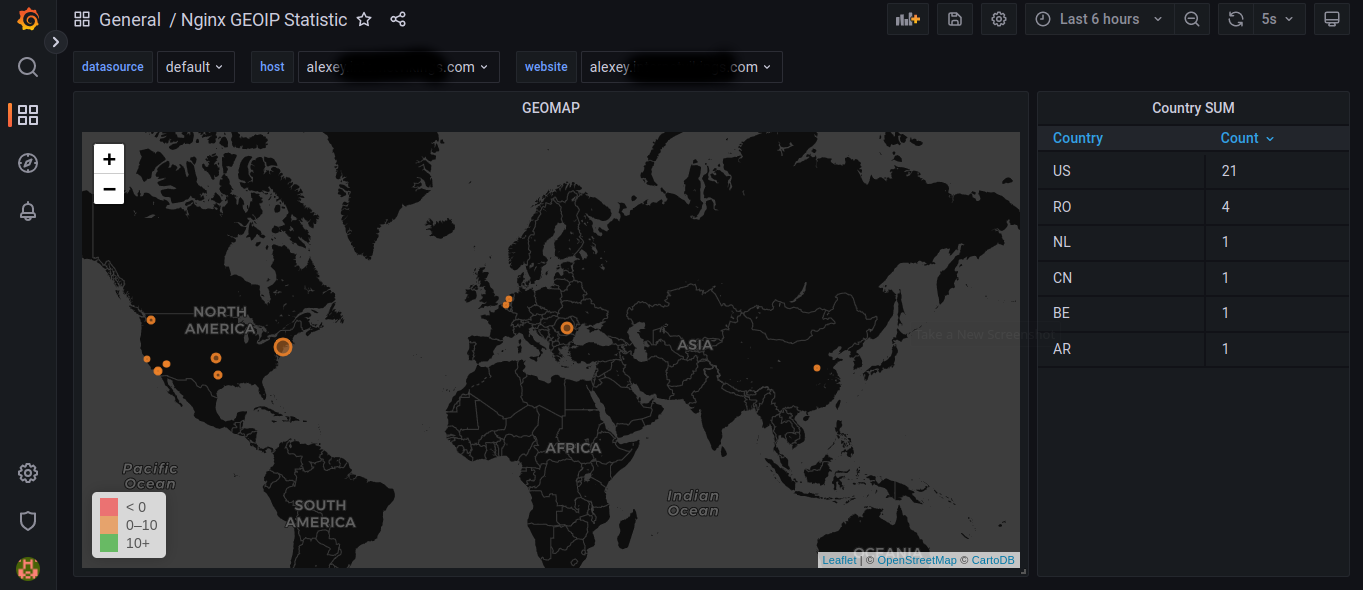
GeoStat a Python-based script for parsing Nginx and Apache log files and getting GEO data about incoming IPs from them. This script converts parsed data into JSON format and sends it to the InfluxDB database, so you can use it for building nice Grafana dashboards. Now, this program supports old InfluxDB 1.8 and modern InfluxDB 2. The application runs as SystemD service and parses log files in "tailf" style. Also, you can run it as a Docker container if you wish.
|
||||
|
||||
# New in version 2.3
|
||||
- Was added the InfluxDB 2 support, now you can use not only old InfluxDB 1.8 but also send data into modern InfluxDB 2.*
|
||||
- Was fixed small bugs also.
|
||||
GeoStat it's a Python-based script for parsing Nginx and Apache log files and getting GEO data from incoming IPs from it. This script converts parsed data into JSON format and sends it to the InfluxDB database, so you can use it for building nice Grafana dashboards for example. The application runs as SystemD service and parses log files in "tailf" style. Also, you can run it as a Docker container if you wish.
|
||||
|
||||
# New in version 2.2
|
||||
- The application was rewritten with adding the availability of parsing more than one log file at one time, now you can parse multiple separated websites on the host. To do that please set up all virtual hosts or websites to save their log files in different places.
|
||||
|
|
|
|||
14
geoparser.py
14
geoparser.py
|
|
@ -5,7 +5,6 @@
|
|||
# geoip, which is going away r.s.n.
|
||||
# Added possibility of processing more than one Nginx log file,
|
||||
# by adding threading support. 2022 July by Alexey Nizhegolenko
|
||||
# Added InfluxDB 2 support. 2022/07/21 by Alexey Nizhegolenko
|
||||
|
||||
import os
|
||||
import re
|
||||
|
|
@ -49,7 +48,7 @@ def logparse(LOGPATH, WEBSITE, MEASUREMENT, GEOIPDB, INODE, INFLUXDB_VERSION,
|
|||
CLIENT = InfluxDBClient(host=INFLUXHOST, port=INFLUXPORT,
|
||||
username=INFLUXUSER, password=INFLUXUSERPASS, database=INFLUXDBDB) # NOQA
|
||||
elif INFLUXDB_VERSION == "2":
|
||||
CLIENT = InfluxDBClient2(url=URL, token=INFLUXDBTOKEN, org=INFLUXDBORG) # NOQA
|
||||
CLIENT = InfluxDBClient(url=URL, token=INFLUXDBTOKEN, org=INFLUXDBORG) # NOQA
|
||||
|
||||
re_IPV4 = re.compile('(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})')
|
||||
re_IPV6 = re.compile('(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))') # NOQA
|
||||
|
|
@ -109,6 +108,7 @@ def main():
|
|||
PWD = os.path.abspath(os.path.dirname(os.path.realpath(__file__)))
|
||||
CONFIG = configparser.ConfigParser()
|
||||
CONFIG.read(f'{PWD}/settings.ini')
|
||||
|
||||
# Get the InfluxDB version so we can parse only needed part of config
|
||||
INFLUXDB_VERSION = CONFIG.get('INFLUXDB_VERSION', 'version')
|
||||
|
||||
|
|
@ -146,14 +146,12 @@ def main():
|
|||
logging.info('Nginx log file %s not found', log)
|
||||
print('Nginx log file %s not found' % log)
|
||||
return
|
||||
|
||||
if INFLUXDB_VERSION == "1":
|
||||
# Run the main loop and grep data in separate threads
|
||||
t = website
|
||||
if os.path.exists(log):
|
||||
t = threading.Thread(target=logparse, kwargs={'GEOIPDB': GEOIPDB, 'LOGPATH': log, 'INFLUXHOST': INFLUXHOST,
|
||||
'INODE': INODE, 'WEBSITE': website, 'INFLUXPORT': INFLUXPORT, 'INFLUXDBDB': INFLUXDBDB,
|
||||
'INFLUXUSER': INFLUXUSER, 'MEASUREMENT': MEASUREMENT,
|
||||
'INFLUXUSERPASS': INFLUXUSERPASS, 'INFLUXDB_VERSION': INFLUXDB_VERSION}, daemon=True, name=website) # NOQA
|
||||
t = threading.Thread(target=logparse, args=[log, website, INFLUXDB_VERSION, INFLUXHOST, INFLUXPORT, INFLUXDBDB, INFLUXUSER, INFLUXUSERPASS, MEASUREMENT, GEOIPDB, INODE], daemon=True, name=website) # NOQA
|
||||
for thread in threading.enumerate():
|
||||
thread_names.append(thread.name)
|
||||
if website not in thread_names:
|
||||
|
|
@ -165,9 +163,7 @@ def main():
|
|||
# Run the main loop and grep data in separate threads
|
||||
t = website
|
||||
if os.path.exists(log):
|
||||
t = threading.Thread(target=logparse, kwargs={'GEOIPDB': GEOIPDB, 'LOGPATH': log, 'URL': URL, 'INFLUXDBTOKEN': INFLUXDBTOKEN,
|
||||
'INFLUXDBBUCKET': INFLUXDBBUCKET, 'MEASUREMENT': MEASUREMENT, 'INFLUXDB_VERSION': INFLUXDB_VERSION,
|
||||
'INODE': INODE, 'WEBSITE': website, 'INFLUXDBORG': INFLUXDBORG}, daemon=True, name=website) # NOQA
|
||||
t = threading.Thread(target=logparse, args=[log, website, INFLUXDB_VERSION, URL, INFLUXDBTOKEN, INFLUXDBBUCKET, INFLUXDBORG, MEASUREMENT, GEOIPDB, INODE], daemon=True, name=website) # NOQA
|
||||
for thread in threading.enumerate():
|
||||
thread_names.append(thread.name)
|
||||
if website not in thread_names:
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ geoipdb = ./GeoLite2-City.mmdb
|
|||
|
||||
[INFLUXDB_VERSION]
|
||||
# Version of the InfluxDB, 1 = old 1.8 and early, 2 = new 2.0 and more
|
||||
# Set this parameter to 1 if you prefer to use an old InfluxDB version like 1.8
|
||||
# Set this parameter to 1 if you want use old InfluxDB version like 1.8
|
||||
# Or set this parameter to 2 if you plan to use InfluxDB version 2.1 or modern
|
||||
version = 1
|
||||
|
||||
|
|
@ -38,7 +38,7 @@ url = INFLUXDB_SERVER_IP:PORT
|
|||
# Token for authentication
|
||||
token = ANY EXISTED USER TOKEN
|
||||
|
||||
# Organization - the name of the organization you wish to write to
|
||||
# Organization is the name of the organization you wish to write to
|
||||
organization = ORGANIZATION NAME
|
||||
|
||||
# Destination bucket to write into
|
||||
|
|
|
|||
Loading…
Add table
Reference in a new issue